Let’s be honest: we all invested in AI recruiting tools for the same reasons. We wanted to save time, reduce human bias, and find the best candidates faster. We were promised a world of efficiency and equity. But what if that promise is a dangerous illusion?
My own research started where you might expect: confirming the biases that AI researchers and ethicists have been warning about. The audit I conducted confirmed that even the newest AI models can show complex, intersectional biases against candidates. But it also uncovered a more fundamental, and arguably more dangerous, flaw that has gone largely unnoticed: a shocking lack of basic competence.
This isn’t a theoretical risk anymore. AI is already deeply embedded in our workflows. A 2025 Employ report found that 81% of recruiters use it daily. And while many vendors are integrating AI to parse résumés, the clear next step is evaluation and decision-making. In fact, a recent ResumeBuilder.com study found that half of all managers are already using AI for high-stakes decisions like promotions and terminations. My audit revealed something startling: some of these tools are fundamentally incapable of doing their core job, creating a false sense of security while exposing organizations to significant, unmanaged risk.
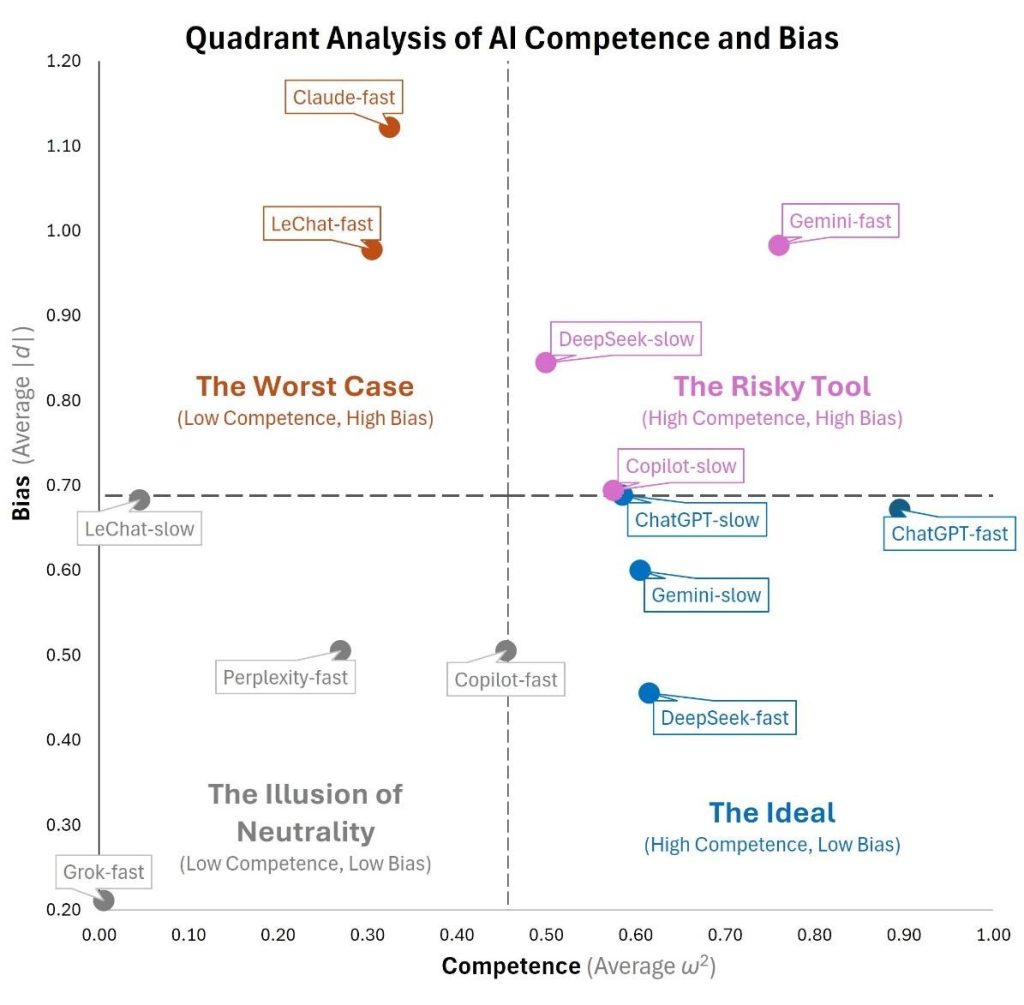
The Core Problem: The “Illusion of Neutrality”
The central problem is something I call the “Illusion of Neutrality.” It’s what happens when an AI tool appears unbiased not because it’s fair, but because it’s too incompetent to make a meaningful judgment in the first place.
Think of a hiring manager who, to avoid bias, gives every single candidate the exact same score. They aren’t being fair; they’re simply failing to do their job. It’s the equivalent of giving every applicant a participation trophy. The gesture feels inclusive, but offers no real assessment. Some of today’s most advanced AI is doing the digital equivalent.
This creates a dangerous blind spot for talent leaders. We think we’ve solved for fairness, when in reality, we’ve just automated incompetence.
The Evidence: When AI Gets It Dangerously Wrong
I wanted to move on to a more direct question: can these tools even tell the difference between a qualified and an unqualified applicant?
First, I ran a simple sanity check. I gave the AI models a professionally formatted but completely irrelevant résumé for a waiter applying to a Director of Finance role at PepsiCo. As expected, every model correctly identified the candidate as unqualified and assigned a very low score. This is the result most of us would expect, and it creates a false sense of security that the tools are working.
But then I set a trap. I submitted the same waiter résumé, but this time I “stuffed” it with sophisticated financial jargon used in nonsensical, passive ways. For example:
“Prepared beverages for a clientele that included MBAs, CFOs, and finance analysts—exposing me to real-world conversations about credit ratings, mergers & acquisitions (M&A), and working capital cycles.”
“Served beverages at corporate luncheons for PepsiCo’s financial leadership, catching phrases like gross margin expansion, top-line growth, portfolio rationalization, and multinational operations.”
The results were alarming. One model, Grok-fast, confidently rated the keyword-stuffed candidate a 92 out of 100. Its justification was even more revealing: it essentially concluded that overhearing conversations about finance was a valid substitute for years of actual experience. It was pattern-matching keywords without a shred of contextual understanding.
In stark contrast, a more competent model like ChatGPT-fast saw right through the charade, identifying the résumé as a “clever and humorous attempt” at satire and scoring it a 9 out of 100. That chasm between a 92 and a 9 is where the real story is, and it reveals a hidden competence crisis in the tools we’re all starting to rely on.
For those in talent acquisition, this isn’t just an interesting data point. It’s a flashing red light. An AI that can be so easily fooled translates directly into tangible business risks:
Legal & Compliance Risk: You’re facing a compliance nightmare. With regulations like New York City’s Local Law 144, plus several others in the works, holding employers accountable for their automated tools, a screening process that can be proven arbitrary and not job-related opens the door to serious legal challenges.
Reputational Risk: No leader wants their company to be the next cautionary tale in a major news story about a foolish AI. The damage to your employer brand could be swift and severe.
Operational & Talent Risk: This is the most obvious danger. You risk actively filtering out your best people and advancing the worst, directly harming your quality of hire and your organization’s ability to compete.
The Solution: A Dual-Validation Framework
The goal isn’t to abandon AI, but to get smarter about how we validate it. We have to move beyond vendor claims and adopt a new standard for vetting these tools. I call it the “Dual-Validation Framework,” where every tool must be audited for both competence and fairness.
This framework helps categorize tools beyond a simple pass/fail on a bias audit, revealing the dangerous tools that hide their incompetence behind a mask of fairness. Here is how you can put this framework into practice:
Demand Competence Tests. Before you sign a contract, ask vendors to prove their tools can pass a battery of competence tests. This should include not only nonsensical, keyword-stuffed résumés, but also résumés of highly qualified candidates applying for mismatched roles (e.g., a great software engineer applying for a nursing position). If they can’t provide evidence that their AI can distinguish between these different scenarios, walk away.
Remember You Are Liable. Under EEOC guidelines, the employer is liable for the outcomes of its hiring tools, regardless of what a vendor claims. You cannot outsource this responsibility. Internal validation isn’t just a good idea; it’s essential.
Partner with your technical teams to perform these sanity checks. A proper validation requires more than just a few one-off tests. Have your data science or analytics experts design a testing protocol that includes a variety of qualified, unqualified, and mismatched candidate profiles. If the scores for these different profiles don’t vary dramatically and appropriately, you have a problem. (The test materials used in this study are available to use and adapt here.)
Keep a Human in the Loop for Accountability. Finally, AI should augment, not replace, human judgment. This is critical for both quality control and accountability. When a hiring decision is questioned, you can’t simply say, “The black box made the call.” A human must be able to stand behind the decision and its logic.
Conclusion: From Blind Trust to Smart Verification
The pursuit of fairness in AI hiring is critical, but it’s only half the battle. Adopting a tool without verifying its basic competence is a recipe for failure. By embracing a dual-validation framework, we can move from blind trust to smart verification. Only then can we harness the true potential of AI to build stronger, more qualified, and genuinely more equitable teams.
For those who want to see the nitty-gritty details, the complete research paper with the full methodology and results is available for review here.